INAPPROPRIATE & ABUSIVE TEXT FILTER
INAPPROPRIATE & ABUSIVE TEXT FILTER
Stop Profanity, Slurs, Harassment & Dangerous Rhetoric with Real-Time Text Moderation.
Mediafirewall AI’s Inappropriate & Abusive Text Filter blocks profanity, slurs, harassment, and predatory language. We detect obfuscated insults, doxxing attempts, grooming innuendo, and incitement before visibility.Multilingual, leetspeak-aware models catch euphemisms, dog whistles, and coordinated abuse patterns. Protect communities, reduce harm, and stay compliant with policy-aware, audit-ready enforcement.
Supported Moderation
Every image, video, or text is checked instantly no risks slip through.
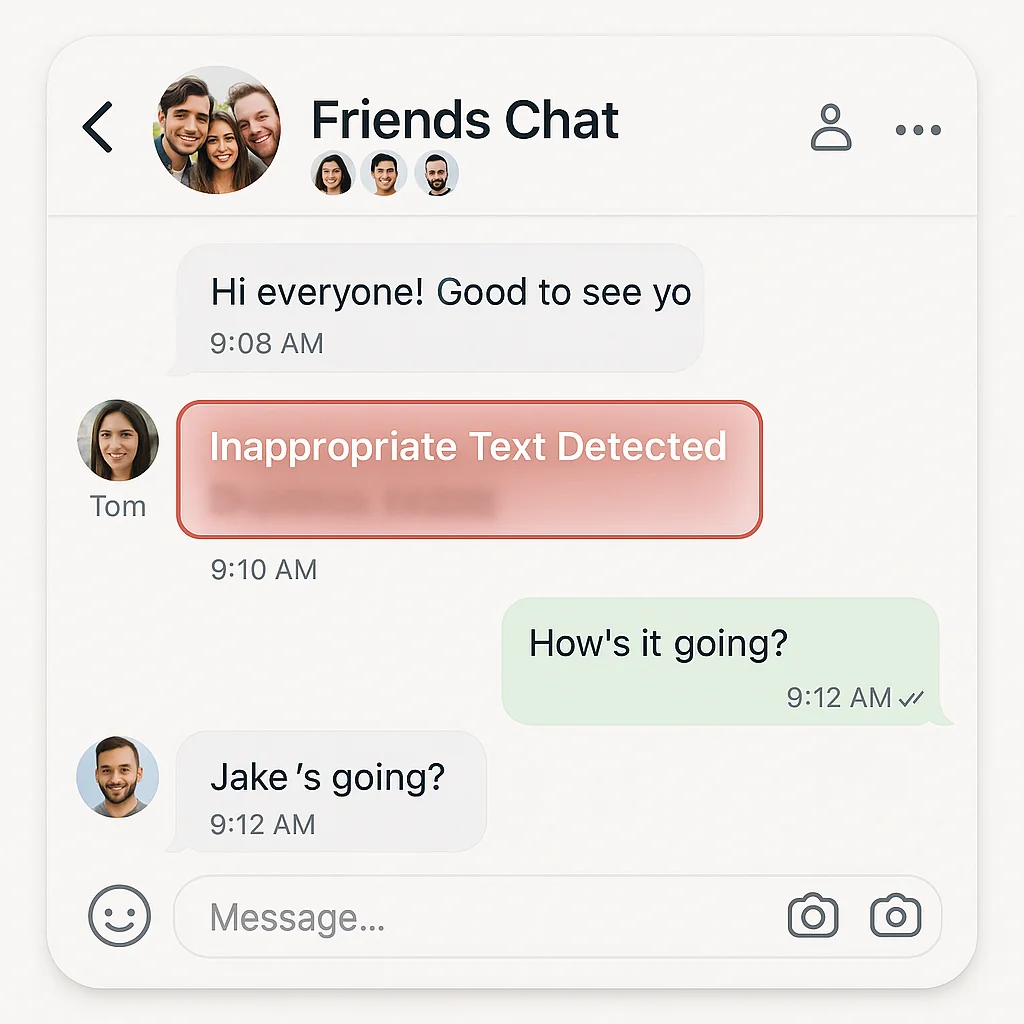
What is the Inappropriate & Abusive Text Filter?
Profanity Control
Catches direct/obfuscated profanity (f***, sh1t, b!tch) and offensive acronyms in chats, comments, and DMs. Pre-publish gating keeps feeds clean and a... Read more
Harassment Shield
Flags threats, bullying, doxxing attempts, and targeted abuse (appearance, disability, identity). Detects gaslighting, dog-whistles, and sustained att... Read more
Sexual Safety
Blocks explicit talk, grooming disguised as compliments, and predatory innuendo. Enforces strict rules on sexual language involving minors.
Incitement Guard
Stops calls for violence, radicalization, and self-harm encouragement.Filters “just joking/free speech” covers used to launder hate.
Anti-Evasion NLP
Understands leetspeak, spacing, unicode swaps, mixed alphabets, and coded slang. Multilingual coverage reduces false negatives across regions.
How our Moderation Works
MediaFirewall AI analyzes messages in real time, detecting harmful tone, phrasing, and abuse patterns. Violations are instantly flagged or blocked—ensuring safe, compliant interactions.
Why MediaFirewall AI’s Inappropriate & Abusive Text Filter?
When harmful language slips through, reputation and safety are at risk. This filter ensures real-time detection of inappropriate text—protecting platforms, brands, and users with uncompromising precision.
Instant Protection Across Every Text Field
From bios to product listings and live chat unsafe language is stopped instantly at the source.
Fully Configurable Policy Settings
Customize what counts as 'inappropriate' across languages, regions, and platform use cases.
Reduces Escalations and Manual Review
With fewer violations reaching users, trust & safety teams spend less time triaging reports.
Auditable for Legal and Policy Teams
Every block is traceable supporting transparency, compliance, and evidence-led enforcement.
Related Solutions
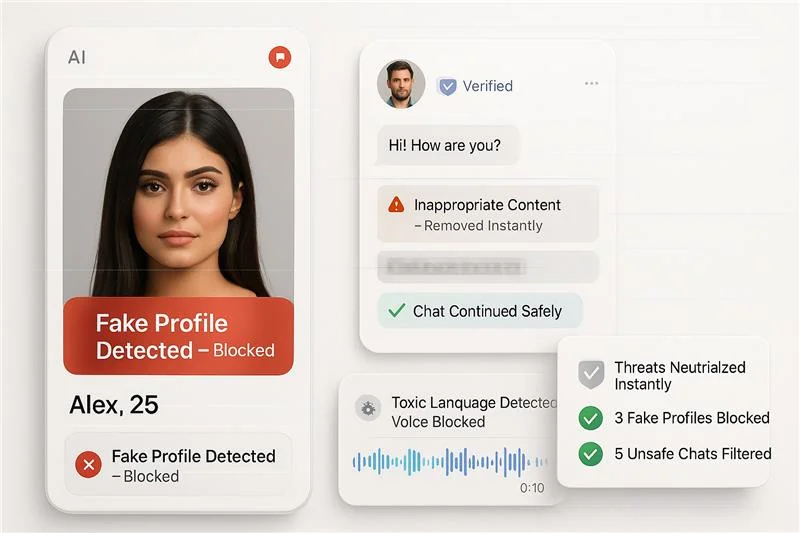

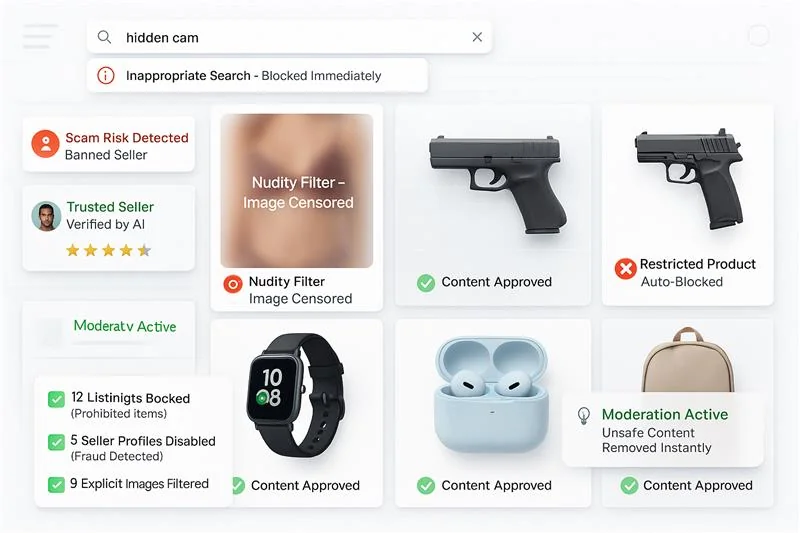
Inappropriate & Abusive Text Filter FAQ
It uses policy-aware NLP to detect profanity, slurs, harassment, grooming, and incitement before text becomes visible, returning boolean, rule-linked actions.
Abusive messages spread quickly in comments/DMs, causing harm and churn; pre-visibility enforcement prevents exposure and repeat abuse.
Pre-publish by default, and on edits/replies in fast threads; continuous checks protect high-traffic conversations.
In leetspeak, spacing tricks, mixed scripts, emojis, hashtags, and quote-tweet/reply chains used to brigand or harass.
Users gain safer interactions; creators and moderators see fewer escalations; platforms improve brand safety and compliance posture.
Yes pattern models spot brigading, gaslighting, dog-whistles, and repetition across accounts and threads.
It blocks grooming attempts, explicit messages, and sexual language directed at minors, with routes to escalate or restrict as your policy dictates.
Decisions include timestamps, evidence snippets, and policy references in audit-ready logs, aligning with GDPR/DSA/COPPA/DPDP and platform rules.